Reporting with Braintrust¶
This guide explains how to use Braintrust to analyze evaluation results, debug failures, and compare model performance.
Overview¶
Braintrust is a platform for tracking and analyzing LLM evaluations. HolmesGPT evals can be used without Braintrust but using Braintrust has a few advantages:
- We can track how Holmes perform over time
- It's easier to run and debug many evals with Braintrust over simpler pytests because Braintrust organises the different components of a HolmesGPT investigation like the input, tool calls, reasoning for scoring, etc.
Setting Up Braintrust¶
1. Create Account¶
- Visit braintrust.dev
- Sign up for an account
- Create a new project (e.g., "HolmesGPT")
2. Get API Key¶
- Click your profile icon (top right)
- Go to Settings → API Keys
- Generate a new API key
- Copy the key (starts with
sk-)
3. Configure Environment¶
Note: Both BRAINTRUST_API_KEY and BRAINTRUST_ORG are required for Braintrust integration to work.
Running Evaluations with Braintrust¶
Basic Evaluation Run¶
export BRAINTRUST_API_KEY=sk-your-key
export BRAINTRUST_ORG=your-org
# Run all regression tests with Braintrust tracking
RUN_LIVE=true poetry run pytest -m 'llm and easy' --no-cov
# Run specific test with tracking
RUN_LIVE=true poetry run pytest tests/llm/test_ask_holmes.py -k "01_how_many_pods"
Named Experiment¶
export BRAINTRUST_API_KEY=sk-your-key
export BRAINTRUST_ORG=your-org
# Run with multiple iterations for reliable results
RUN_LIVE=true ITERATIONS=10 EXPERIMENT_ID=baseline_gpt4o MODEL=gpt-4o poetry run pytest -m 'llm and easy' -n 10
# Compare with different model
RUN_LIVE=true ITERATIONS=10 EXPERIMENT_ID=claude35 MODEL=anthropic/claude-3-5-sonnet CLASSIFIER_MODEL=gpt-4o poetry run pytest -m 'llm and easy' -n 10
Key Environment Variables¶
| Variable | Purpose |
|---|---|
UPLOAD_DATASET |
Sync test cases to Braintrust |
EXPERIMENT_ID |
Name your experiment run. This makes it easier to find and track in Braintrust's UI |
MODEL |
The LLM model for Holmes to use |
CLASSIFIER_MODEL |
The LLM model to use for scoring the answer (LLM as judge) |
Analyzing Evaluation Results¶
Output¶
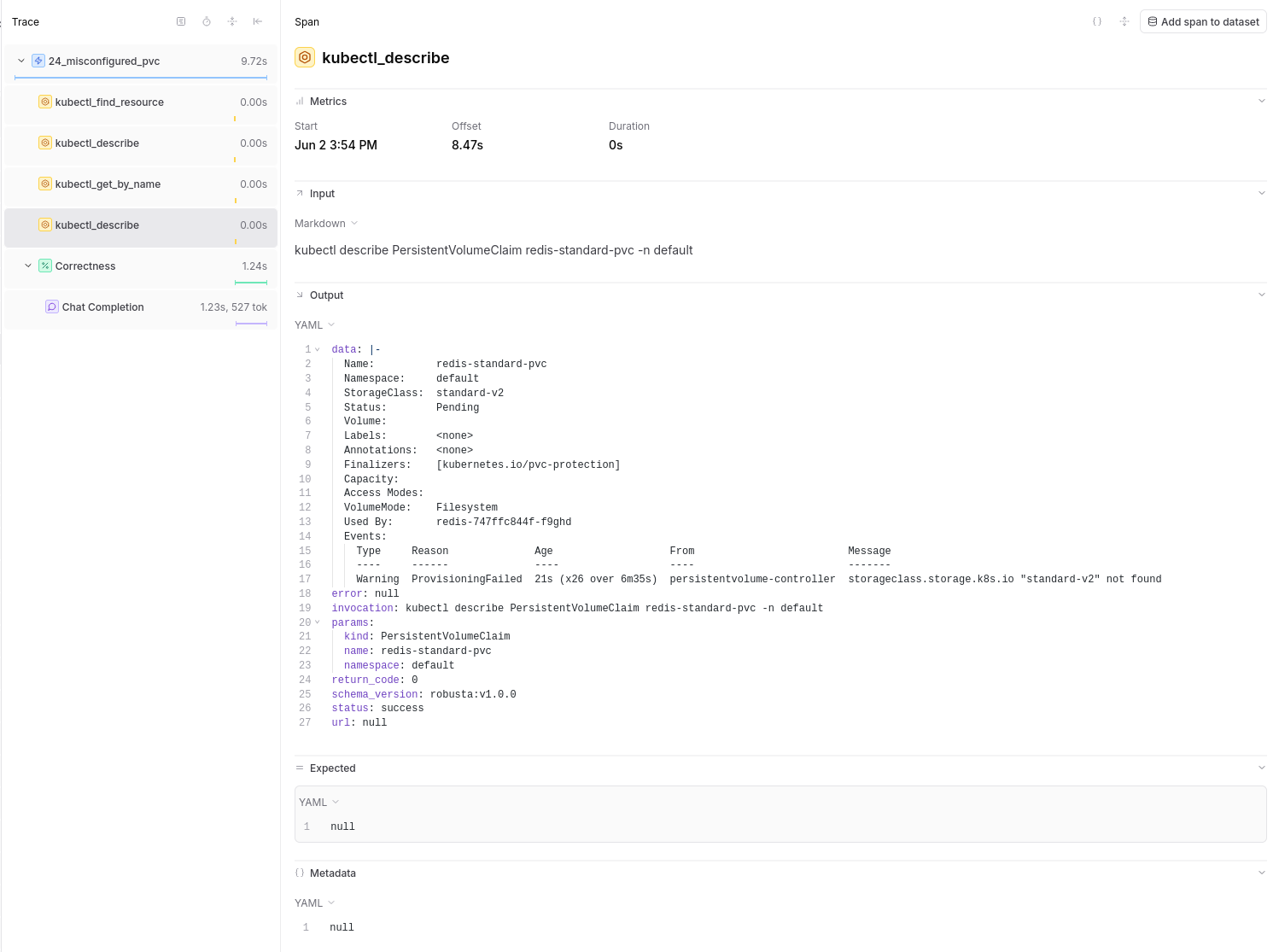
The main Span of an evaluation will present the input (either the AlertManager issue or the user's question for Ask Holmes) as well as HolmesGPT's answer.
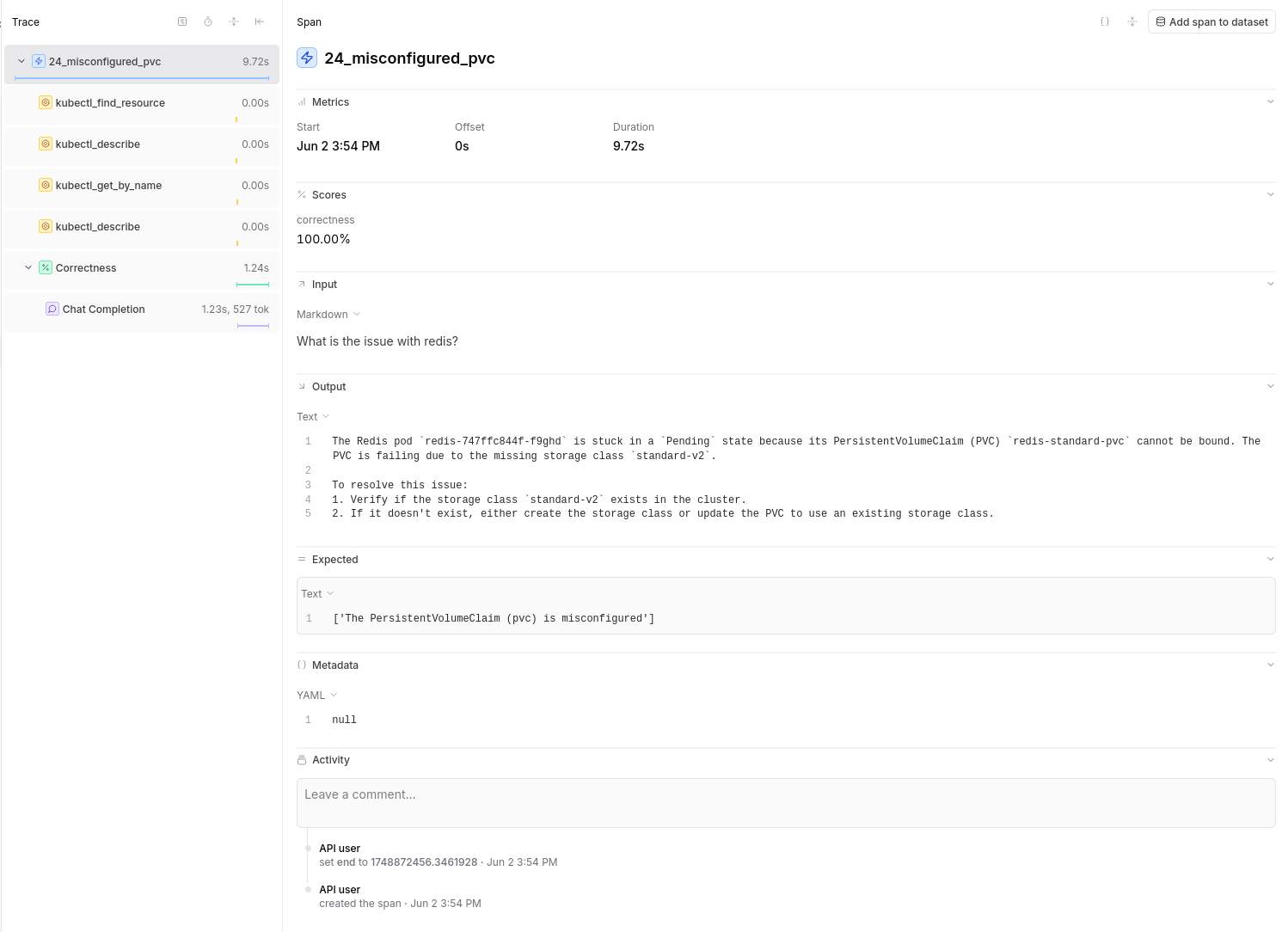
Score Types¶
Correctness Score: - Measures accuracy of LLM responses - Values: 0 or 1 - Shows how well output matches expectations
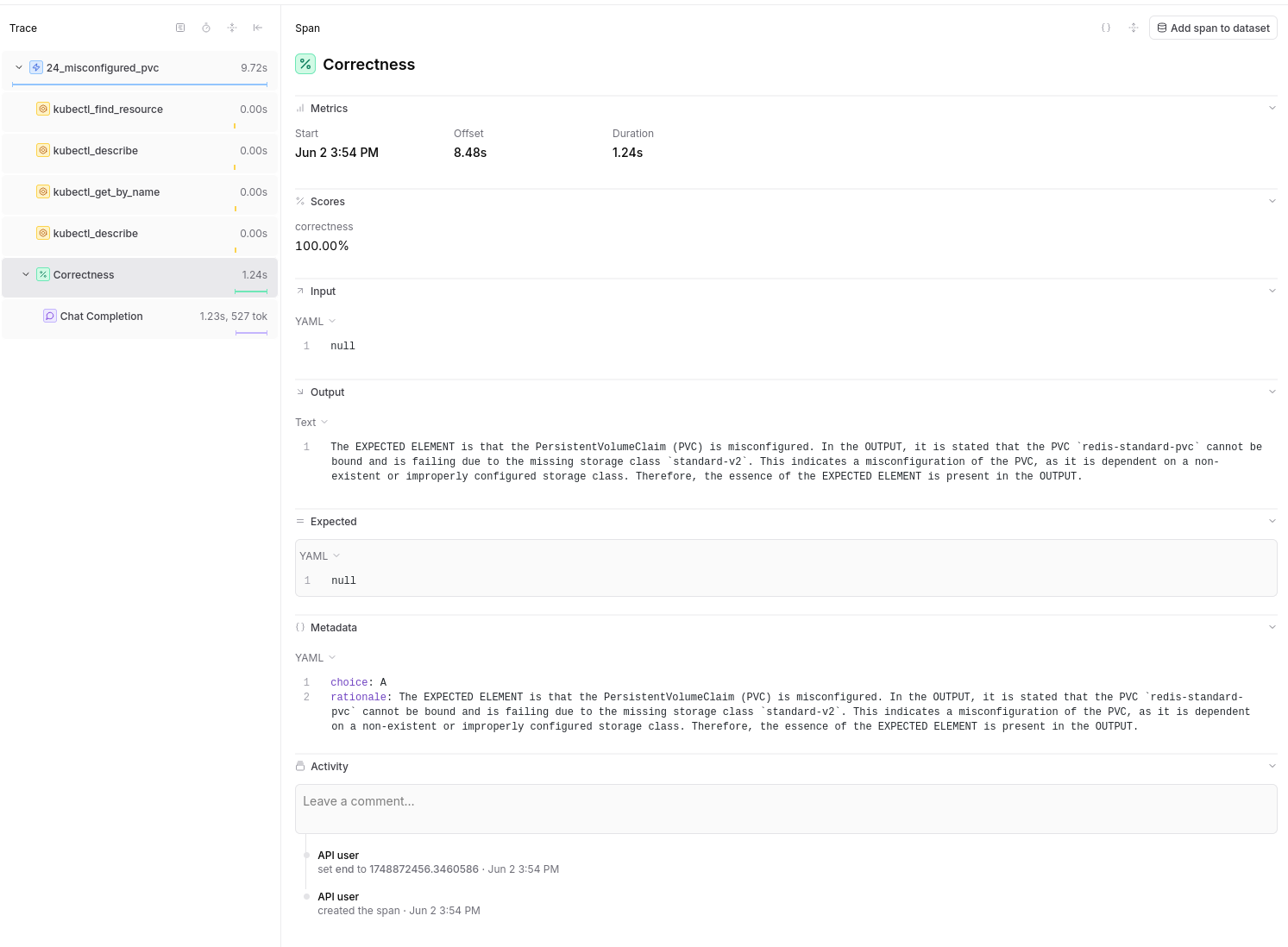
Debugging Failed Evaluations¶
1. Identify Failing Tests¶
In the experiment view: - Sort by score (ascending) to see worst performers - Filter by specific score types - Look for patterns in failures
2. Examine Tool Call Traces¶
Click on a failing test to see: - Input: The original prompt/question - Tool Calls: Which tools the LLM invoked - Tool Results: What data each tool returned - Output: The LLM's final response - Expected: What the test expected